






Introduction
Maintaining big databases was and still is a problematic task for developers. Huge datasets tend to limit the API and optimization always becomes one of the priorities, especially in web development where server’s reaction time is essential. Luckily, there is a simple and effective way to optimize executed data reading queries in SQL (e.g. SELECT) and it is called “indexing”.
Index is basically a structure which holds the value that the table column is filtered by as well as a pointer from each record to their rows in the table where the data is actually stored. Indexes are great optimizers for any SQL reading queries, implemented in almost every SQL engine today. Their main advantage emerges when our API is focused on reading and providing data to the end user as the existence of indexes negatively impacts the speed of executing data saving queries (e.g. INSERT).
Unfortunately, many developers are treating indexes as an “auto-magical” feature that provides “free” speed optimization without any downsides. One must remember, though, that optimization is not all about fast results but it is also connected to wise and reasonable resource allocation and responsible disc space management.
In this article, I will try to explain how we can bring indexing to another level, introducing customizable and specific indexes in order to optimize them for particular API cases. For this task I will be using one of the most famous SQL systems – PostgreSQL as well as Django Rest Framework as an API.
B-tree index
By default, PostgreSQL provides us with a very simple yet effective type of index – a B-tree index. This type of index is the most common in use. It achieves its goal by creating a tree structure of blocks containing key values in ascending order. Each of these blocks references another two child blocks, where left side keys keep value lesser than the current keys and the right side ones are more than the current keys. This way seeking values inside an index comes up to simple comparison calculations. B-tree can also handle equality and range queries on data that can be sorted into an ordering.
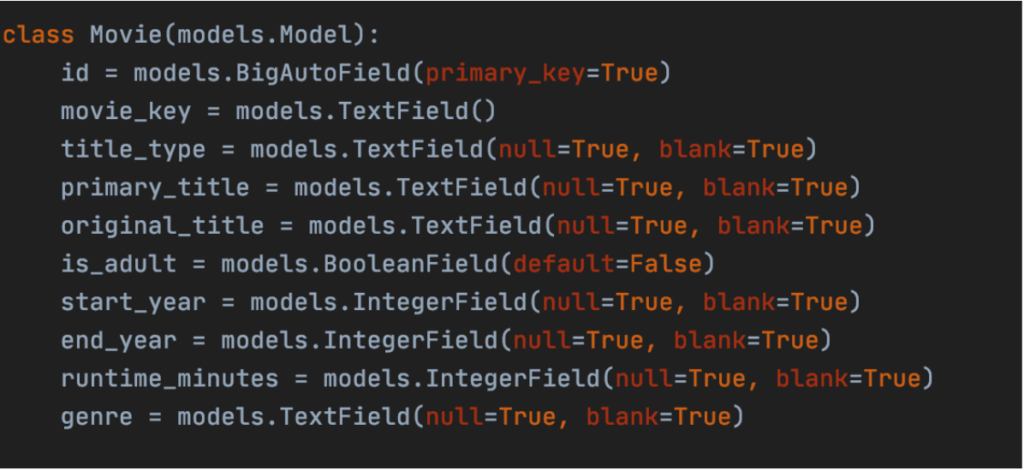
A simple comparison between using a B-tree index and “no index” scenarios can be shown in the following example. For the purpose of this task I used a subset of “IMDb movies” dataset, which contains more than 9 million rows of movies or TV series episodes data and is available for free on their website: https://www.imdb.com/interfaces/. Django model for that dataset is as follows:
In the example below we are performing a simple lookup query – retrieving the movie’s original_name by unique movie_key value. Using “Django Debug Toolbar” middleware we are able to see SQL queries performed during the request as well as a full query plan with execution time.
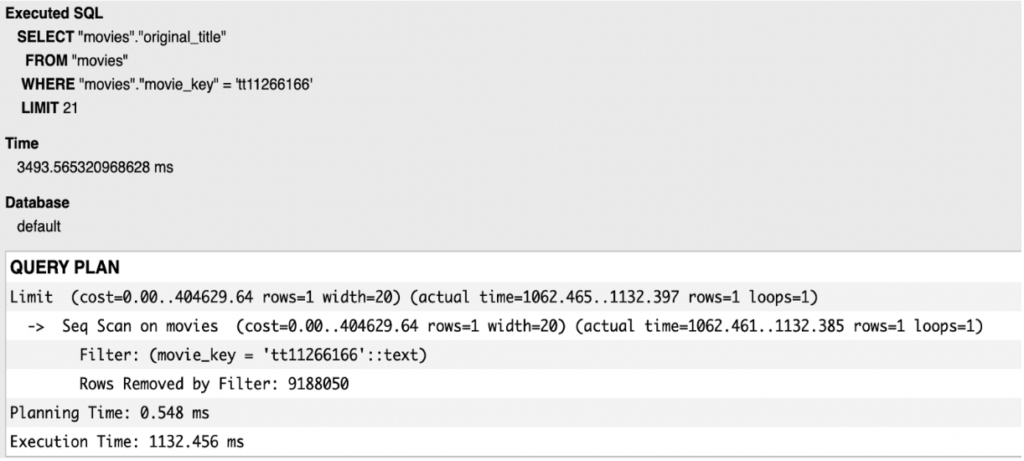
It’s clear that PostgreSQL “decided” to use sequential scan to retrieve the item, which simply means that it had to scan all table rows to finish its action. This practice has a clear impact on execution time value. Therefore, to improve the performance of the API, we should use an index on the movie_key field. Thanks to Django, we can make this change directly in our model by applying db_index=True in the desired field. After running the database migrations and sending the request once again, we can see the change in the executed query.

This time, the database engine used index scan on the index automatically created by PostgreSQL. This means that no sequence scanning was performed as the engine searched the index tree by providing a specific movie_key value. The execution time is significantly lower this time, coming down to less than 1ms.
At this point many developers would finish their work stating that there is no room for further improvement. Surprisingly though, there is a way to optimize this query even more, allowing the database to skip the part of searching the table at all. This is achievable using a covering index.
Covering (inclusive) index
Covering indexes allow to include additional column values inside the index structure and fetch them during an index scan. This way we can enforce using “Index Only Scan” by our SQL engine. They are useful when performing “value-for-value” lookups, which means retrieving one column value in the table based on another one. The index can be set up in the Meta class of our model. Additional field value is added in the include parameter of the UniqueConstraint index. We must remember to remove the previously created B-tree index from the field.
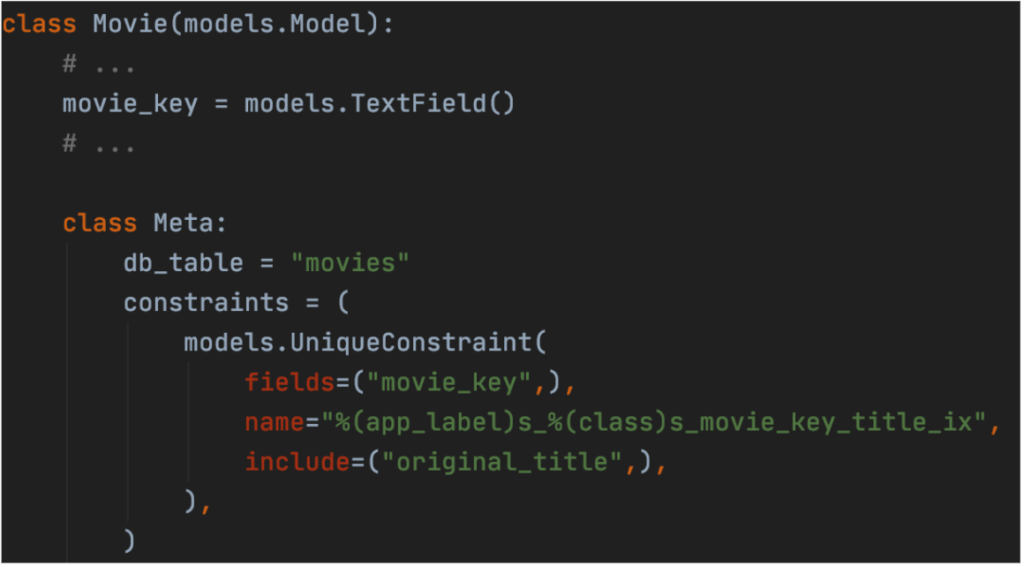
Execution plan presents itself this way:

This time, SQL engine used index only scan. It means that it did not have to seek the database table at all, retrieving data directly from the index structure which is highly beneficial. One of the drawbacks is that the index size has increased since there is more data included inside of it.
Covering Index – Summary:
- Allows to execute query without accessing the table (Index Only Scan).
- Great for simple “value-for-value” lookups.
- Increases the size of an index.
Partial (condition) index
The next API goal would be to filter out all rows which type is not “movie”. Our table consists of more than 9 million entries, most of which are TV series episodes and shorts. Below, we can see how the query is executed without any added index:
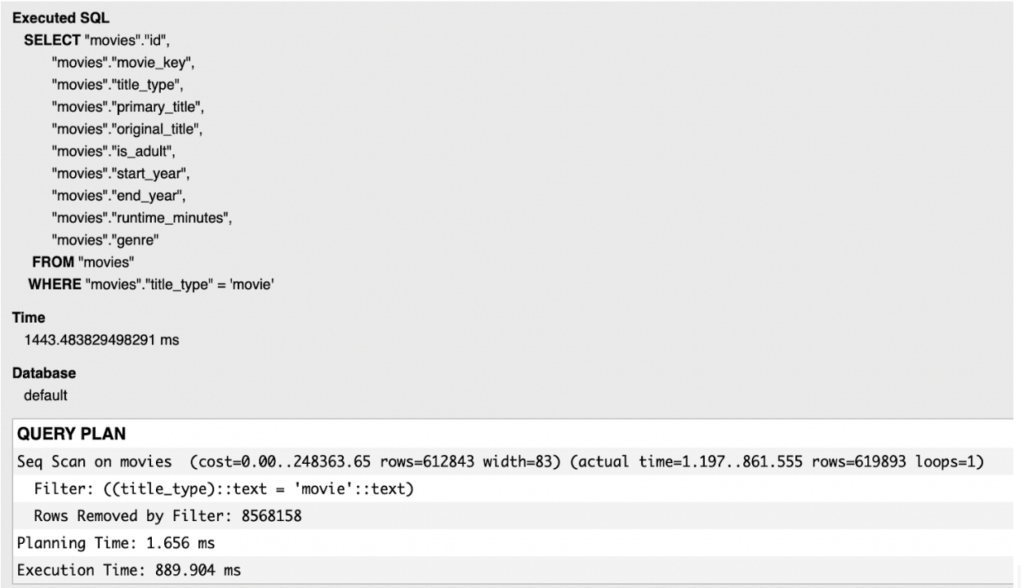
Using sequential scan resulted in almost 900 ms of execution time. We might try to optimize it using a B-tree index on the title_type field. After adding an index to the model and running Django migrations, the results are as follows:
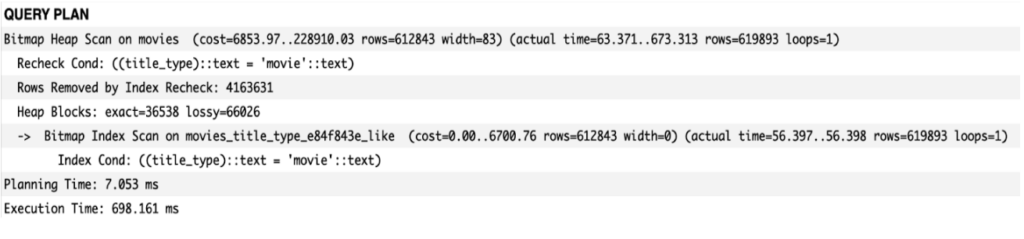
We were able to optimize the query using index scan. Unfortunately, when taking a brief look at the PostgreSQL console and revealing an index list, one might see that the size of this very simple index is quite big, reaching 62 MB.

Many developers tend to forget that created indexes require disc space the same as the database table does. It is undoubtedly a problem as optimization should also stand for reasonable resource management in our projects.
The issue we encountered (and an implementation hint as well) is that “movies” make only about 7% of the whole table rows. Therefore, it would be reasonable to include an index only on those entries that satisfy the expression: title_type=”movie”. Partial index allows us to fix this problem by indexing only part of the table column based on a provided condition. Its implementation is very straightforward:
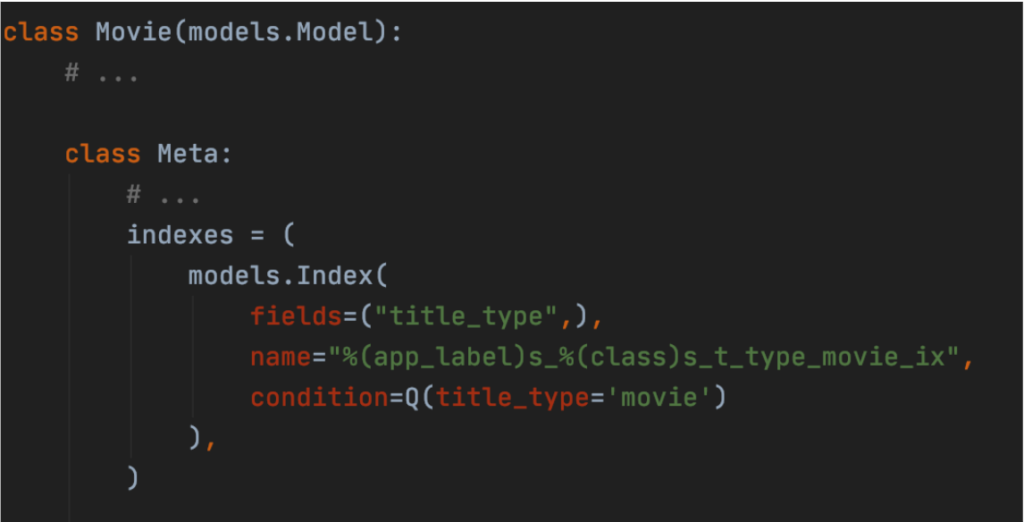
After running the request once again, we see the results:
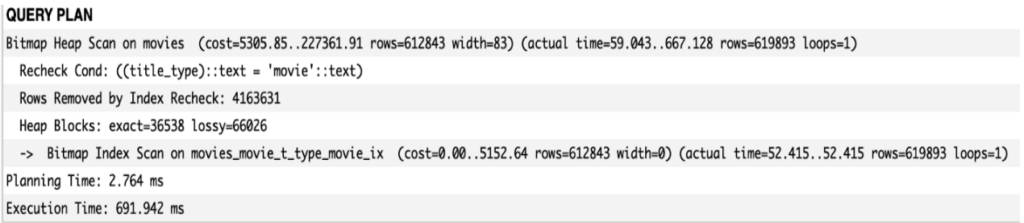
It is clear that the database engine used the index we have just created. The execution time has not changed but true optimization can be seen in disc space. After listing existing indexes in the PostgreSQL console we see that, thanks to Partial Index, we were able to reduce index size 7 times.

Partial Index – Summary:
- Great for reducing index size.
- Does not affect query speed.
- Great for nullable columns.
- Most efficient when a column is limited by its values set.
Hash Index
Sometimes in our API we might encounter a need to perform a “reverse lookup”. In our case it would be searching for movie_key based on the original_title value of a movie. Performing this kind of query without index is rarely optimal which can be clearly seen in the execution plan below.
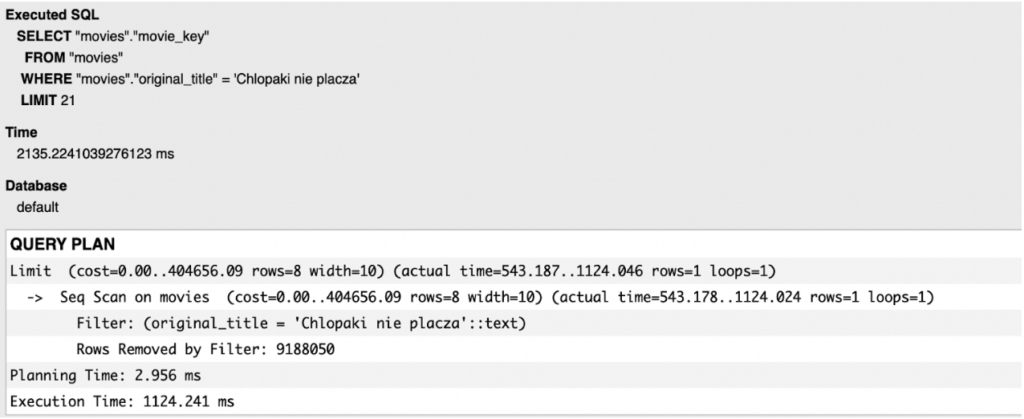
Adding an index on the original_title field would greatly improve the performance of this view.

Unfortunately, the cost we would pay is, without a doubt, the disc space as keys for such strings as movie titles tend to be long. In our case, we were able to optimize execution time almost 8000 times but the size of a newly created index is almost 700 MB which is equal to about 23% the size of the whole table.

A quick and easy solution to that problem is using the PostgreSQL feature called Hash Index. It works by applying hash functions to column values and assigning those values into containers called “buckets”. It is most efficient when data in a column is almost unique. We can use it by importing the PostgreSQL-specific package. Luckily, it is available in Django.
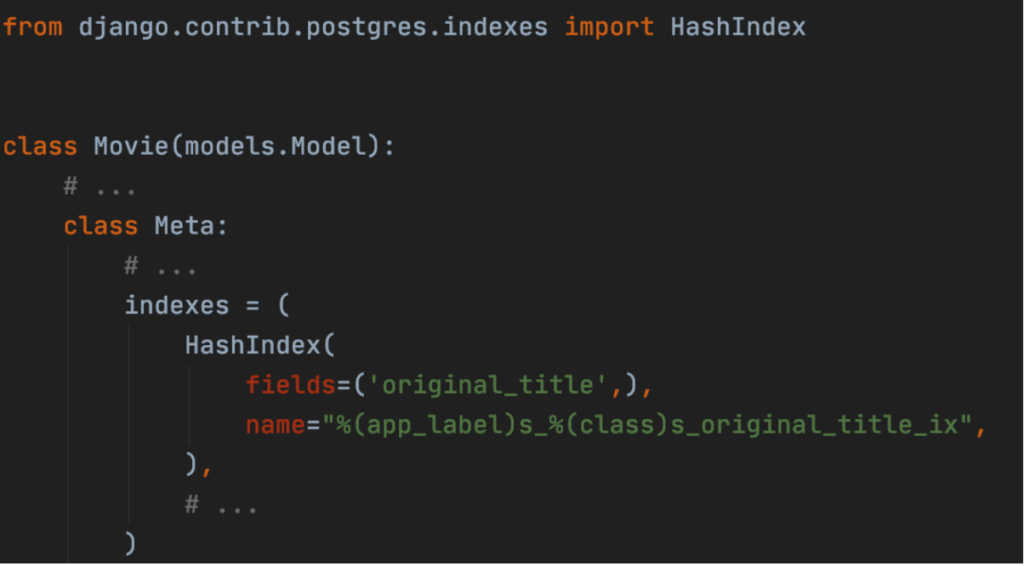
After applying changes to the model, deleting the former index and running migrations, let us send the request once again.

When running a query once again we might see that Hash Index has no impact on execution time. In specific situations it might even optimize the speed of the request. The true advantage of using it is visible in the index size.

Newly created index size stands for about 38% of what B-Tree index was taking in disc space. Thus, with just a few lines of code we were able to greatly optimize our resource usage.
Hash Index – Summary:
- Reduces index size.
- In specific scenarios, it optimizes speed.
- Great for big-size almost unique values.
- Inefficient when column data consists of similar values.
- Does not allow for index sorting, composite and unique values or range search.
Block Range Index (BRIN)
Our last example would be to find entries rows which have start_year above specific integer value. In our case, we try to find the latest movies, released in 2022 or to be released in the future.
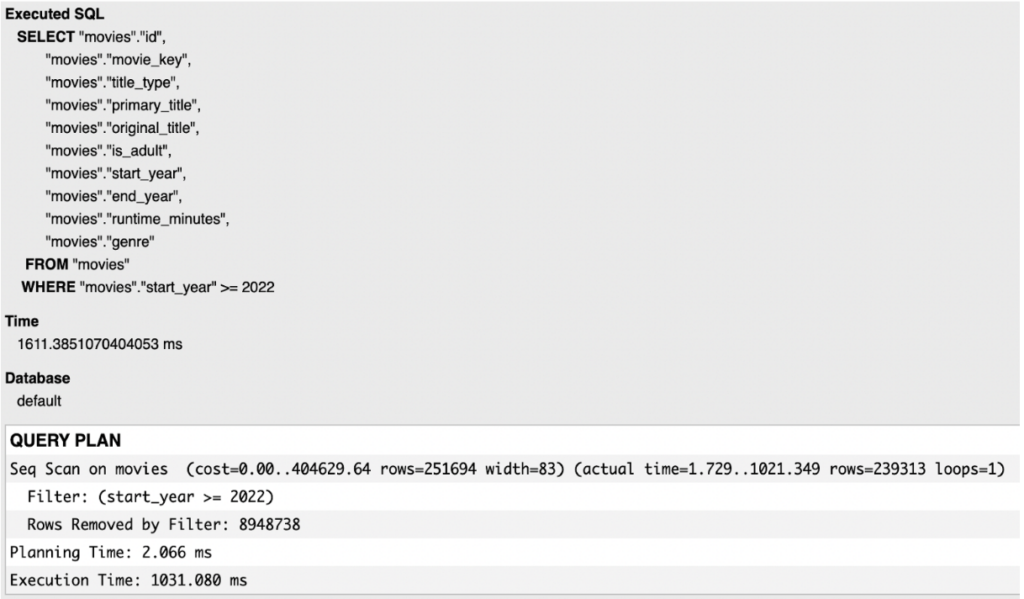
Now, let us apply an index on the start_year field to improve the query speed.
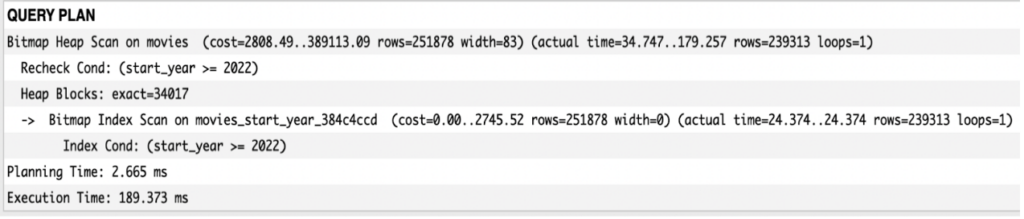
Applying an index worked once again in terms of execution time optimization. Unfortunately, we encounter the same problem as before when checking the index size which reaches about 61 MB.

The conclusion is simple – the index size is quite big, or at least could be smaller. Luckily, there is one index that fits perfectly to our current situation.
BRIN Index stands for “Block Range Index” and it groups values in a column into ranges of JSON pages. This PostgreSQL-specific feature works best when data is naturally sorted on disc, which suits our example where start_year values start from about the 1870s and end in years beyond 2022. Main advantage of that situation is that they are sorted in our table in ascending order.
Using BRIN index requires importing the same package as Hash Index:
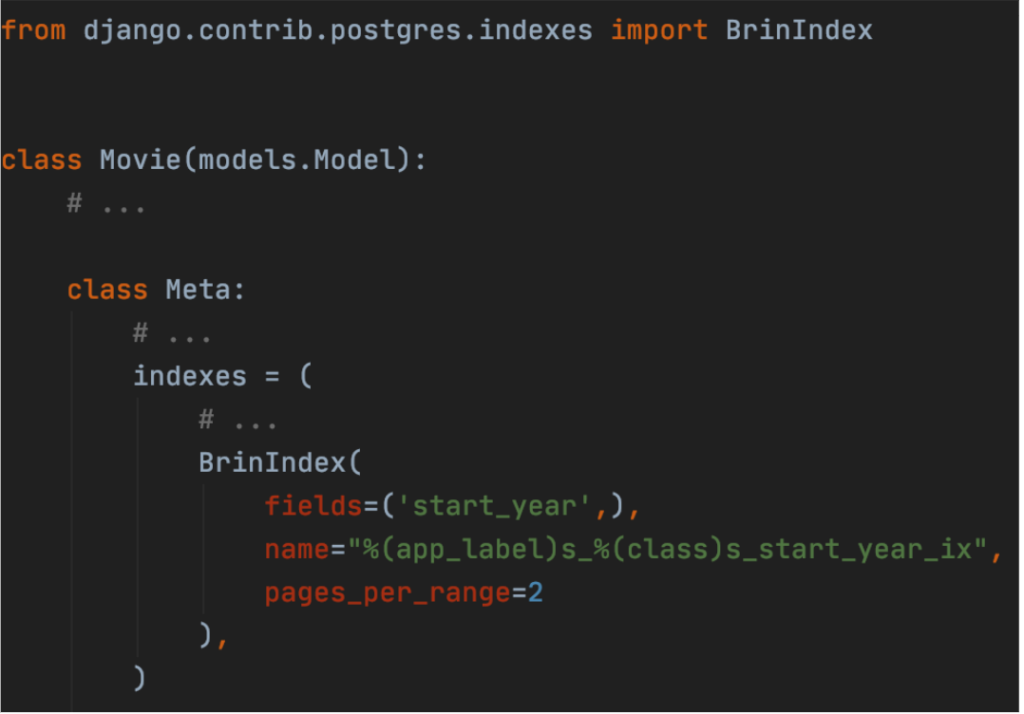
Now, let us send the request one more time.
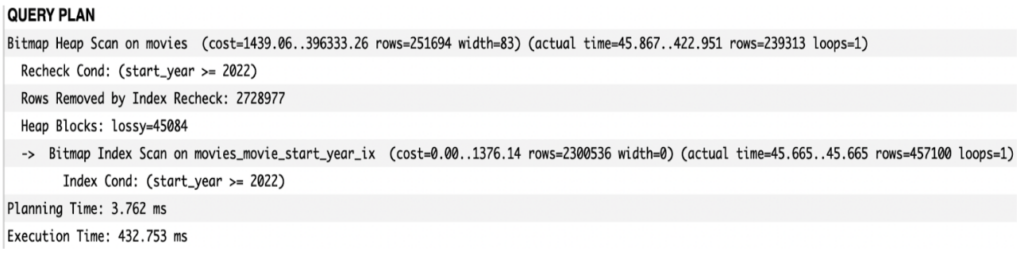
When we check the query we might see that the index was properly used by the database engine. Unfortunately, the execution time is slightly bigger than when we used the B-Tree index. This is because the BRIN indexes require more time since they check all the values within the buckets. The exchange is that it optimizes disc space, in our case we were able to use about 19 times less space (3376 kB to be exact).

There is a way to ensure better optimization of the execution time for the BRIN index. The solution is to experiment with the pages_per_row value in the index itself. This might slightly increase the index size so one must strike a balance here.
Hash Index – Summary:
- Largely reduces index size.
- Great for any “created_at” dates or naturally growing values in a column.
- Might be useless when data is not naturally sorted on disc.
- Does not optimize speed.
Conclusions
Shown examples have proven that there is more than just a B-Tree index that can be used for optimizing our queries. One must remember that optimization stands not only for speed of execution but it’s also connected to responsible disc space management and CPU usage. Thanks to engines like PostgreSQL, we are provided with numerous useful index types which might suit our API needs, while most of them are simple to use and easily integrate with web frameworks like Django. Last but not least, responsible developers must remember that introducing any new index will negatively impact the speed of saving new entries into the database table (e.g. running INSERT query). There is always a balance one must strike in order to find a perfect golden mean between reading and creating data in any API. Nevertheless, it is always worth using indexes as their usefulness cannot be overestimated.
Sources
- PostgreSQL official documentation:
https://www.postgresql.org/docs/current/indexes.html - PostgreSQL-specific indexes in Django documentation:
https://docs.djangoproject.com/en/4.1/ref/contrib/postgres/indexes/ - Re-Introducing Hash Indexes in PostgreSQL:
https://hakibenita.com/postgresql-hash-index - IMDb dataset:
https://www.imdb.com/interfaces/

 Andrzej Kopera • Sep 05
Andrzej Kopera • Sep 05

