




Extracting data from documents using latest Machine Learning techniques
Companies need to process a lot of business documents like resumes, financial reports, receipts, invoices and many more. Automation or even optimization of those tasks can substantially improve the efficiency of data processing flow in a company.
In answer to this demand, new methods and techniques have been invented. They are a part of a relatively new topic: Document Intelligence. It focuses on analyzing and processing semi-structured printed documents (also called visually rich documents). Basically, it is the output of programs like MS Word or LibreOffice. The techniques are often based on statistics, heuristics, computer vision or machine learning.
Today we will talk about the LayoutLMV2, the method based on machine learning and computer vision, recently published by Microsoft (May 2021). The model and the method are published however, some details are unavailable yet.
Technical introduction
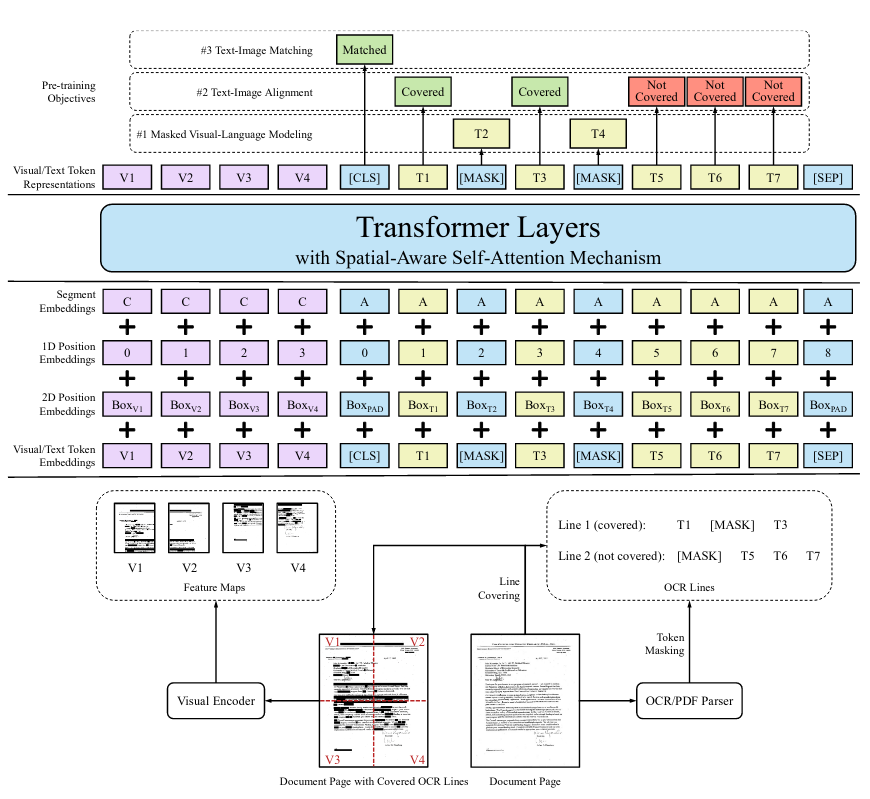
The method uses ideas from 2 different Machine Learning architectures: Transformer and ResNext-FPN. They come from two different domains: Natural Language Processing and Image Processing. It combines efforts of both, to process their textual and visual information about the given document.
Natural Language Processing
The architecture of this model is very similar to the Transformer one. The information represented at the embedding level, we can guess, does not deviate drastically from the method presented in the original transformer publication.
The document is processed into the sequence of visual/text embeddings of constant size. The embeddings are nothing more than vectors of identical dimension (length) filled with floating-point values. Those embeddings represent elements of the document, that is, words or images of the document.
We said that the length of the embedding sequence is constant, but what if the document would not contain enough content to fill all the places in the input sequence? Then all the left spaces are padded with special values representing the empty values.
The words are likely transformed into the vector representation similar to those created from the methods like Word2Vec. It works by transforming each word into a vector with embedded knowledge about their meaning. You can find a clearer explanation here.
Also, like in the transformer model, we must artificially provide the information about the position of each encoding. I guess the researchers applied similar sinus/cosine technique used in original Transformer Paper. Here you can find a great explanation of how it works.
Image Processing
As I have already mentioned, the model expects a sequence of vectors as an input. We managed to turn words into vectors. Let’s do the same thing with visual information.
What I can assume from the paper, the image of the document is passed into the ResNeXt-FPN model to create some number of processed parts of the image (ROI-regions of interest). The images are processed into the feature map generated by this variant of residual network. The feature map is the result of applying many filter operations on the image. The “compressed” image is then stretched from 2D image values to a long 1D vector to produce a result.
The image of each document page is resized and passed into the ResNeXt-FPN model. As the result we get 3d map of features: 7 in width, 7 in height and 1024 in depth. The first two represent normal image dimensions, and the depth represents the features in each area of the image. This “compressed” image is then stretched into a 2D map: 49 by 1024 consisting of floating-point numbers.
Like in the word representation, position of image is provided in similar fashion as in the word embeddings.
Logic underneath
LayoutLM, in opposition to the other Machine Learning techniques, leverages both Computer Vision and Natural Language Processing models strengths. In the method, the 5 types of information in document are added:
- Textual information – meaning of the text
- Layout information – horizontal and vertical alignment of the text in pixels
- Position information – index of each element in the sequence
- Visual data – visual representation of the document
- Segment data – this part is closely related to the way the words are getting processed by the WordPiece algorithm in the tokenizing part of the model.
The results
We obtain similar structure of results as in other models using Transformers architecture. You may recon the name Transformer because it is used in famous ML models, such as GPT-3 or BERT.
Just like other models from this family, this one works particularly well in pulling out the knowledge from the semantic structure of a given data (in this case visually rich document). It could learn, how we, as humans, like to lay out the different parts in the document. For instance, how we tend to put placement of our signature in the bottom right location.
What is more, it has inherited some cons like massive model size (426 million parameters in Large model, so around 2 GB space used on the disc) and reliance on massive amounts of data and compute resources to train. Fortunately, the second con could be partially omitted by using the technique known as fine-tuning.
It allows us to reuse and fit the model into our specific task. For example, let us say we want our model to work well with receipt data. As a result we would need a tiny subset of data for the training process.
The published model has been already pre-trained on massive amounts of data from the IIT-CDIP dataset. It contains about 11 million photos of scanned documents. The dataset contains various types of documents, such as forms, questionnaires and news articles.
The model could be trained to perform given tasks:
- Data tagging – we can leverage our model to parse documents. This task is particularly hard, so the requirement is that the given documents must be similar in structure. Documents such as CVs would be too hard to process, but something like receipts are just fine.
- Document Classification – we can group our documents by their structure similarity. We can categorize documents into letters, resumes, invoices and many more groups.
- Question Answering about the document – this could be used in combination with for example, chatbots that can easily evaluate the documents which client has sent to us. This task is hard to perform so, for the current state of the research, this functionality would be limited.
Obviously, this explanation is vastly simplified. The mechanism of how the information about the word content and its position are combined is much deeper and complicated, and it is impossible to fit in this one blog post.
How to use LayoutLMV2 model (example with code)
The LayoutLMV2 like many other NLP models such as GPT or BERT are easily accessible from the hugging face website.
To perform basic demo we will use the part of the example taken out from their website. The performed task is “tagging different parts of the document”, which could be leveraged to fetch some necessary information from the document. You do not need to install or have any technical knowledge to test out this model for yourself.
https://colab.research.google.com/drive/1CGrVNcShIcJPLXPAgHMgGD9XbOhFhRVA?usp=sharing
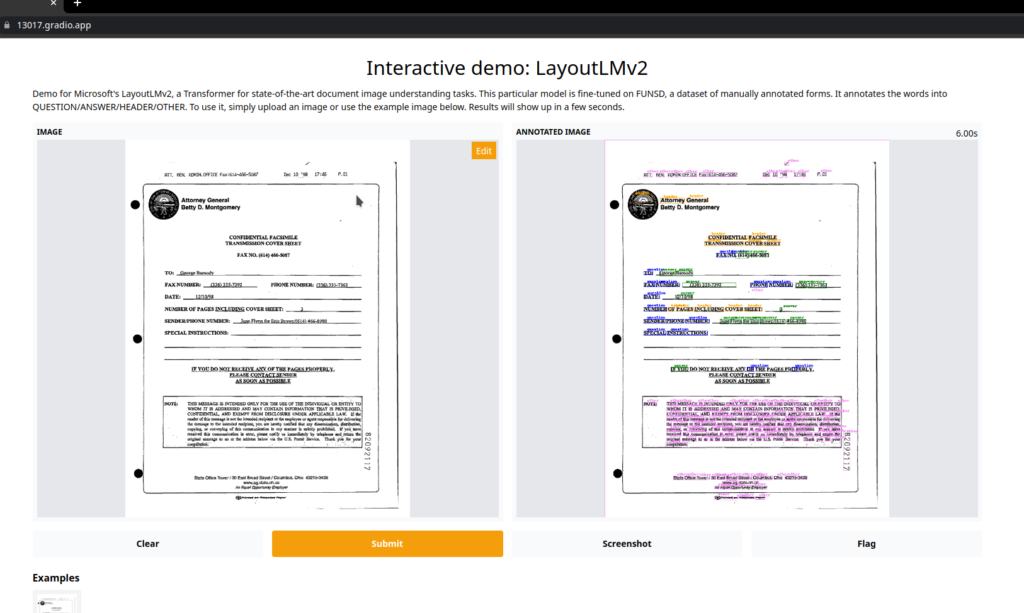
I believe that the potential for this model to be used in the production environment is very high. It can be narrowed down to perform specific task by using the fine-tuning method to make our model work on specific data. In opposition to other ML techniques, this one is very cheap to test out. All we need to do is to add little amounts of data for this operation, and we could experience current State-of-The-Art level quality of the results. It could be easily integrated into some kind of microservice application when used in combination with some popular python web frameworks like Fast API.
Footnotes
1Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, & Lidong Zhou. (2021). LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding.
2Xu, Y., Li, M., Cui, L., Huang, S., Wei, F., & Zhou, M. (2020). LayoutLM: Pre-training of Text and Layout for Document Image Understanding. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining.
4Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, & Illia Polosukhin. (2017). Attention Is All You Need.
5Xinying Song, Alex Salcianu, Yang Song, Dave Dopson, & Denny Zhou. (2021). Fast WordPiece Tokenization.